How to Build a Better RAG Pipeline: Complete Guide
LLMs don't know your data. RAG bridges that gap. Master ingestion, extraction, chunking, embedding, and real-time sync.
Key Takeaways
- A production RAG pipeline has 5 stages: ingestion, extraction, chunking & embedding, persistence, and refreshing
- LLMs don't know your enterprise data - RAG bridges that gap by connecting AI to internal docs, CRM records, and more
- Production systems need retries with exponential backoff, access controls, encryption, and audit trails
- Semantic chunking outperforms fixed-size chunking by 30–50% in retrieval relevance
- Needle handles all 5 pipeline stages out-of-the-box with direct integrations to Slack, Jira, HubSpot, and more
The Challenge
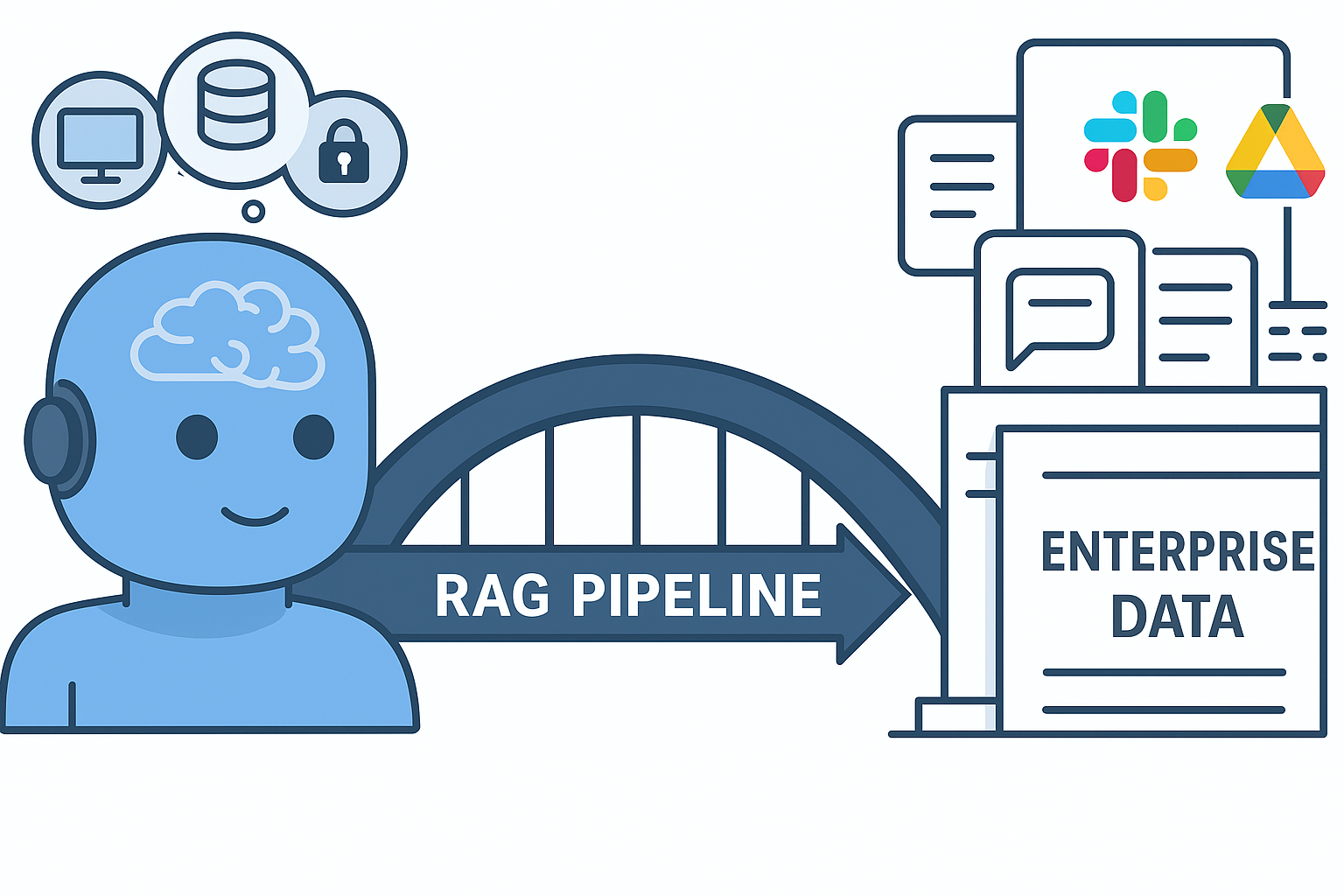
LLMs don't know your enterprise data - internal docs, customer conversations, CRM records, technical specs, compliance documents. Without access to this context, even advanced AI becomes just another search engine. RAG (Retrieval-Augmented Generation) bridges this gap by giving AI access to your private knowledge base at query time.
The 5-Stage RAG Pipeline
- Stage 1 - Ingestion: Identify and connect knowledge sources (wikis, SaaS tools like Slack, Jira, HubSpot, Google Drive)
- Stage 2 - Extraction: Convert complex PDFs, tables, images, and spreadsheets into clean, useful text
- Stage 3 - Chunking & Embedding: Split text into semantic segments, convert to vector representations. Semantic chunking improves retrieval relevance by 30–50% over fixed-size methods.
- Stage 4 - Persistence: Store vectors in an optimized database (e.g., PostgreSQL with pgvector) with metadata for filtering
- Stage 5 - Refreshing: Keep data synchronized with source systems in real-time so answers always reflect the latest information
Build vs. Buy: RAG Pipeline Comparison
| Consideration | Build from Scratch | Use Needle (RAG-as-a-Service) |
|---|---|---|
| Time to production | Weeks to months | Minutes to hours |
| Connector integrations | Build each one manually | Pre-built (Slack, Jira, Gmail, Drive, etc.) |
| Document extraction | Custom parsers for each format | Intelligent extraction built-in |
| Real-time sync | Implement webhooks, polling, queues | Automatic synchronization |
| Security & compliance | Build access controls, encryption | Enterprise security built-in |
| Ongoing maintenance | Team manages infra, updates, scaling | Fully managed service |
Production Considerations
- Reliability & error handling: Retries with exponential backoff, dead-letter queues, graceful degradation
- Security & compliance: Access controls per collection, encryption at rest and in transit, full audit trails
- Performance & scale: Ingestion throughput, sub-second query response times, cost-optimized embedding models
Needle's Approach
Needle handles all 5 pipeline stages out-of-the-box: direct integrations with enterprise tools, intelligent extraction for complex documents, semantic chunking and embedding, optimized vector storage, and real-time synchronization across all connected systems - with enterprise security built-in.
Summary
Building a production RAG pipeline requires 5 stages: ingestion from enterprise tools, extraction of text from complex documents, semantic chunking and embedding, vector persistence, and real-time data synchronization. Each stage introduces production challenges around reliability, security, and scale. Building from scratch takes weeks to months and requires ongoing infrastructure maintenance. Needle provides all 5 stages as a managed service with pre-built connectors for Slack, Jira, Gmail, Google Drive, and more - letting teams go from zero to production RAG in minutes instead of months.
Start with Needle and focus on use cases that drive business value. Read the complete guide.